

What the interns have wrought, 2023 edition
We’re once again at the end of our internship season, and it’s my task to provide a few highlights of what the dev interns accomplished...

We’re once again at the end of our internship season, and it’s my task to provide a few highlights of what the dev interns accomplished...

OCaml with Jane Street extensions is available from our public opam repo. Only a slice of the features described in this series are currently implemented....

Jane Street is excited to announce our sponsorship of SoME3, Grant Sanderson and James Schloss’s third Summer of Math Exposition. SoME is a contest that...

OCaml with Jane Street extensions is available from our public opam repo. Only a slice of the features described in this series are currently implemented....
OCaml with Jane Street extensions is available from our public opam repo. Only a slice of the features described in this series are currently implemented....

Our traders and researchers love Python for its agility and for its huge open-source ecosystem, especially when it comes to machine learning. But the heavy...

At Jane Street we use a pattern/library called “expect tests” that makes test-writing feel like a REPL session, or like exploratory programming in a Jupyter...

In 2022 a consortium of companies ran an international competition, called the ZPrize, to advance the state of the art in “zero-knowledge” cryptography. We decided...

The Dojima rice market, established around 1716, is widely considered to be the world’s first organized futures exchange. Instead of directly exchanging money for rice...
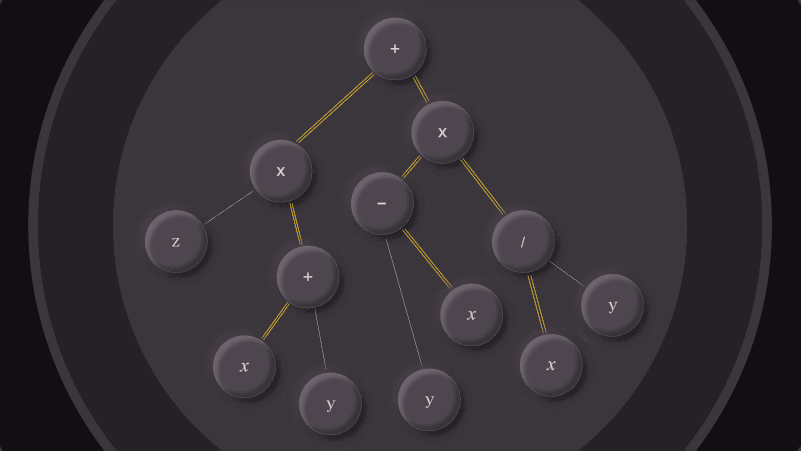
One of the problems we wrestle with at Jane Street is how to understand and manage the costs associated with the positions we hold: things...

We are excited to announce the launch of the Jane Street Graduate Research Fellowship!
We’re once again at the end of our internship season, and it’s my task to provide a few highlights of what the interns accomplished while...

We are excited to announce research internships in our Tools and Compilers group.
Software engineering intern candidates often ask how team placement works and how much input incoming interns have over their teams and projects. We know team...

Intel Processor Trace is a hardware technology that can record all program execution flow along with timing information accurate to around 30ns. As far as...

We spend a lot of time on education at Jane Street. Like, really a lot.

We recently restructured our standard libraries at Jane Street in a way that eliminates the difference between Core_kernel and Core and we’re happy with the...

It’s the end of another dev internship season, and this one marked something of a transition, since halfway through the season, NY-based interns were invited...




